Its been a long time since I’ve written VHDL and I’ve since forgotten which version of my microcontroller I’m on – my filing system says 6 but I’m feeling a bit sceptical, 6 rewrites seems a bit extreme!
Regardless, I’ve since been deciding what I should do for my final year project and one of the projects was the full implementation of a microcontroller (soft core) in VHDL for an FPGA. While I don’t think I’m going to take it as a year long project, it put me in the mood to resume my own microcontroller.
Having not really paid much attention to my microcontroller for a fair few months, I decided to rewrite and improve on the instruction set along with general architecture. Previously, I managed to get my processor running at 120MHz but due to the architecture, this was only equivalent to 24MIPS, pretty inefficient realistically.
Architecture Updates
- Pipelined instruction fetches – All instructions internal instructions take 1 cycle (ALG, JPZ – without the branch taken, BIT). Writing to memory take 1 cycle extra (2 cycles in total) and reading from memory takes 2 cycles extra (3 cycles in total). Program jumps take 1 extra cycle (2 cycles) regardless of if it was a conditional or absolute jump, unless it is popping a value from the PC stack and jumping to it, that takes 2 extra cycles (3 cycles in total).
- The processor has 3 main states: Execute, Stall and MemOp. During execution, the processor expects a new instruction on every cycle. If this is known to be guaranteed, the processor will stay in this state on the next clock cycle. If however the processor has had to change the PC, the next queued instruction from the PC and instruction fetcher (one module) will be irrelevant. This is somewhat equivalent to predicting branches are never taken (if branches are never taken, code flows linearly and continuously). Memory operations take an extra couple of clock cycles so the program counter is stalled for on or two cycles (dependent on a memory read or write) so it doesn’t over-fetch instructions.
- Inclusion of new instructions: BIT, RET, RTC, STK, JPO, JPR
I guess now would probably be the best time to explain what all these new instructions do!
BIT – This instruction can manipulate single bits in the registers. I’m still sticking to a 4 register stackless architecture. Bits can be set, cleared or toggles using this instruction
RET – This instruction is used to pop a program address off the PC stack and jumping to it
RTC – This instruction is the same as above, it however allows the storage of a constant value upon returning into one of the four registers
STK – This instruction disables or enables pushing and popping to the PC stack. Writing the stack variable to 1 using: “stk 1”, will allow for any jump instruction to push the current PC value onto the PC stack
JPO – This instructions allows for increasing the PC by a constant amount e.g. if the PC was at 4, calling “JPO 10” would increase the PC to 14
JPR – Finally, this instruction allows for the PC to jump to an address located in a register
This leaves the total list of instructions as:
- STR – Store constant
- MTR – Memory to register (absolute address)
- MRR – Memory to register (address from register)
- RTM – Register to memory (absolute address)
- RRM – Register to memory (address from register)
- ALG – Arithmetic and logic
- INC
- DEC
- ADD
- SUB
- Logical shift right
- Arithmetic shift right
- Logical shift left
- Equal (Rdst = Rsrc)
- Not
- And
- Or
- Xor
- BIT – Bit manipulation
- JPZ – Jump if a register is zero
- JMP – Absolute jump
- JPO – Offset PC
- JPR – Jump to address in register
- STK – Enable/disable pushing the PC to the PC stack
- RET – Return from routine (pop address from PC stack)
- RTC – Return from routine (pop address from PC stack) and store constant in register
As anyone who can count can see, there are 14 instructions, I can therefore qualify this as a MISC processor (<32 instructions according to wikipedia)!
I’ve also made a couple of minor changes to my assembler. I can now write lines like “str ra ‘function” and this will store the absolute address of the “function” subroutine into register a.
There are however lots of different jump instructions. I’ve justified the amount as each one allows me to do something different as I’ll show in the examples below.
Examples
Copying values into RAM from program memory
This is a very standard microcontroller operation and is generally implementable on nearly any microcontroller I can think of. Its prodominantely used for copying initalization values for RAM locations or peripherals from flash. Like with PIC microcontrollers, my architecture doesn’t allow me to read data from the program menu without trying to execute it. I’ve got around this by the inclusion of the RTC instruction which allows a constant to be stored in a register upon the return of a subroutine. This means I can declare a subroutine of lots of RTC instructions with the data I want to store and in conjunction with the JPR instruction, I can jump through this subroutine copying data from it into RAM. I’ve written and tested a program that stores 10 values in RAM locations 5-15.
str ra 10 #10 Values to copy
str rc 8 #Starting position in RAM
str rd ‘array #Memory location of data
‘copyloop
alg dec ra #Decrement data counter
stk 1 #Enable PC stack pushing
jpr rd #Jump to address in RD
rrm rb rc #Copy data from RB to RAM(RC)
jpz ra end #If RA = 0, jump to end
alg inc rc #Increment memory address
alg inc rd #Increment memory offset
stk 0 #Disable PC stack pushing
jmp ‘copyloop #Jump to top of loop
‘array
rtc rb 1 #Random data to copy to RAM…
rtc rb 20
rtc rb 300
rtc rb 40
rtc rb 5
rtc rb 17
rtc rb 16
rtc rb 14
rtc rb 12
rtc rb 10
Program listing for a mass memory copy
Surprisingly, all of the code above including data only consumes 22 words of space where obviously, 12 of those words are required for the loop to work. This could be expanded to whatever array size with minimal overhead, up to 65535 bytes of data. With a 100MHz clock in simulation, this whole process takes 1500 ns, or 150 cycles.
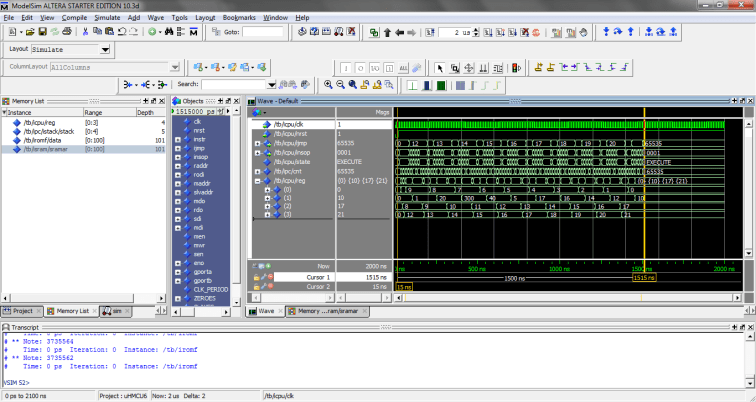 Simulating the whole data copying process
Simulating the whole data copying process
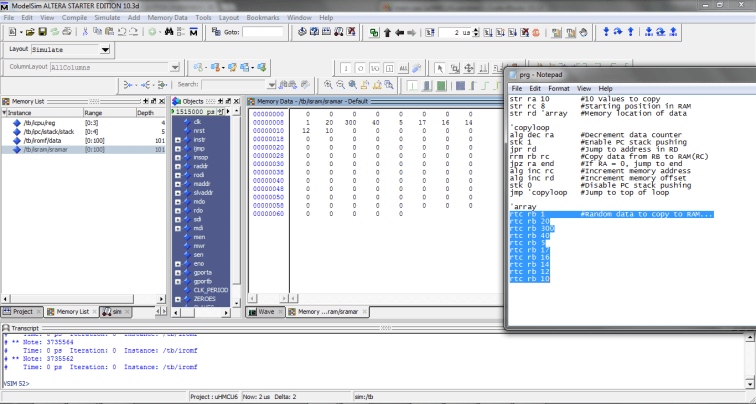 The data matches!
The data matches!
As of yet, I’ve not tried synthesizing this version of the processor though I did a simpler version and managed to get it running at ~93MHz which while the clock speed is slower than my other CPU, total throughput is much faster!
Keep tuned for further updates!

One thought on “HMCU V1…2…3…6?”