With work looming over me (starting tomorrow infact…) I’ve decided to further progress my C implementation of the HMCU. As a bit of a challenge with strings, I decided to build myself a compiler. While its fun writing instructions in Excel, its a bit of a pain because you have to know your powers of 2 well and where commands should go. This was a problem for early programmers too and is what pushed for a “higher level” language. This led to assembly language, essentially a text version of the byte codes so the coders didn’t have to remember every machine code/use complex lookup tables for the machine codes.
As early programmers experienced machine code writing problems, I’ve also got to to that point too! Writing a bit in the wrong bitfield can cause mayhem in a program, destroying the chances of your virtual machine working correctly. This led me to writing a simple assembler! This might seem a simple step but in my life so far, I’ve never actually delved into formally learning assembly, stupid right? Actually, that is a slight lie. For my A2 electronics exam, I had to learn some PIC assembler – that didn’t actually come up on the exam anyway!
Regardless, I’ve further improved my language to now consist of only 11 instructions now, leaving room for up to 53 more instructions! Some might call this future proofing, others just laziness. I’ve managed this by combining the logic and arithmetic instructions into two standard instructions, LGC and ARH, respectively. Within each of these instructions, is the option to perform each logic operation: and, or, nand, nor, xor, xnor, invert, less than, less than or equal to, equal to, more than or equal to and more than, along with specifying which two registers will be operated upon and which register will contain the result. The same applies to the ARH instruction, with each operation being: add, subtract, multiply, divide, modulo, left shift and right shift.
With these further improvements, while it makes the virtual machine programming easier, it makes the actual programming of the machine harder as bytecodes become more intricate, further pushing me to produce an assembler. This leads me to explaining how my assembly works:
Currently, I haven’t implemented the ability for labelled sections of code. All code is linearly translated from a txt file, directly to the machine codes (of course, with some error checking!) meaning the code has to have an instruction per line or the parser will flag an error. Regardless, it certainly eases up on the program writing and programs can be written much faster than previously. The assembly structure is like so:
<Line number> <Instruction> <Op command 1> <Op command 2> <…Op command n> #Comment
I’ve written the lexer, parser and translator in C++ as it makes string operations a load easier, a rarity for me! The parser converts each line into individual tokens, seperated by the space character ‘ ‘, ignoring the initial line number and stopping the parse once a ‘#’ is encountered. The “compiler” is actually a pretty small program, accounting to 321 lines of C++ code though a lot of it is written as short hand (2 line if else statements), along with the actual virtual machine at 169 lines of code. An assembler and virtual machine in less than 500 lines of code!
Testing the assembler:
To test the assembler, I’ve essentially used the same programs as in my previous test, just instead of writing them in bytecode, I’ve written them in assembler format. The first program I tested was the GCD of two numbers, as done previously. Rewriting this ins assembly was really simple since I’d already written it in byte code format. The code looks like:
0 STR RA 50 #Store 50 in RA
1 STR RB 30 #Store 30 in RB
2 LGC == RA RB RD #(RB=RA) result into RD
3 JPR SET RD 10 #Jump if RD is set
4 LGC > RA RB RD #(RA>RB) result into RD
5 JPR SET RD 8 #Jump if RD is set
6 ARH SUB RB RA RB #RB = RB-RA
7 JMP 2 #Jump to ADDR 2
8 ARH SUB RA RB RA #RA = RA-RB
9 JMP 2 #Jump to ADDR 2
10 PRT 0 #Print
11 BRK #Exit
The line counter at the side helps when decided where the program needs to jump to. This program compiles to:
04 00 00 32 04 40 00 1E 14 00 12 C8 2A C0 00 0A 14 00 16 C8 2A C0 00 08 10 00 06 41 24 00 00 02 10 00 06 08 24 00 00 02 20 00 00 00 1C 00 00 00
Which is complex enough to read and look up against my program chart! Running the program however works fine.
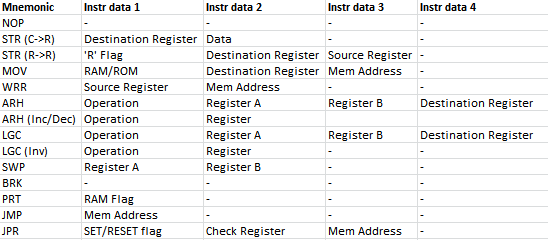
Excel is still useful however at writing out the instruction table!
As can be seen above, STR, ARH and LGC instructions have two entries. These are because the instruction structure changes for these instructions. For example, storing a constant in a register (C->R) would look like STR RA 1234 where as storing one register in another would look like STR R RA RB. This is similar to the increment and decrement instructions, to increment a register, you would write ARH INC RA, where as multiplying two registers would be ARH MUL RA RB. This is similar once again to the logic instruction. To invert a register, you would write LGC INV RA, where as and’ing together two registers would be LGC AND RA RB.
I haven’t yet implemented the ability to use labels so jump statements still need to jump to the line numbers as all jump statements really do is set the PC to the new position.
Not bad progress for an evenings work eh! I’ve currently got a friend of mine helping me work towards getting a C compiler written too.
